- 成為GPT高手
- 梁成睿
- 1069字
- 2025-06-03 14:19:49
1.2.1 GPT的上限
對比之前出現的各種模型,GPT存在以下顯而易見的優勢。
1.超長文本理解生成能力
超長文本理解生成能力是GPT模型最直觀的優勢。之前的模型大多是簡單的文本處理模型,擁有基礎的分詞能力,專注于單個問題的對答,如大家手機上的智能助手。而GPT通過注意力機制將理解和生成連貫文本的篇幅提升到之前模型難以望其項背的程度。
注意,現在使用的服務通常有單條對話長度限制,以及對話數量的限制。這不是模型本身的限制,而是注意力機制使然(當然,也可以說是模型本身的限制),隨著GPT理解和生成的文本數量變長,它的算力要求是直線增長的。
驗證這個說法最典型的方式就是輸入一本長篇小說的內容,可以發現不是所有的數據都能被輸入進去,而是在達到模型上限以后丟棄了部分數據。
2.多樣性和創造力
GPT理解和生成的過程是與內容無關的,這使模型能夠生成多種風格和主題的全新內容,具有一定的創造力。
人們能夠在一定程度上控制這種創造性,如NewBing可以使人們選擇生成的內容是有創造力的還是偏精確的;ChatGPT的開發API使用Temperature參數來控制AI的“腦洞”,Temperature參數的值越高,AI生成的內容就會越傾向于脫離參考內容。
更加令人震撼的是,GPT的創造力足以進行零樣本學習,即GPT之前沒有學習過不要緊,只要用戶以一兩段對話讓其學習即可。無論是屬于個人的寫作風格,還是行業最新的處理方法,只要舉幾個例子,之后就可以將同類問題交給GPT解決了,如圖1.3所示。
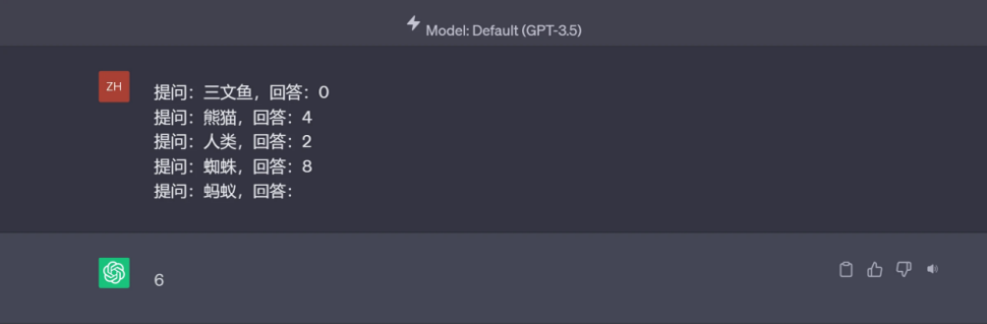
圖1.3 一個GPT學習的例子
3.知識轉義
GPT模型的原理造就了語言無關特性,可以將輸入文本轉換為語義表示,也就是說,AI不再拘泥于具體語言、文本符號等表面的意義。這種特性使GPT呈現了另一種令人驚嘆的實用能力——與語言無關。也就是說,無論是什么語言的資料,在GPT眼里都是一樣的,且GPT不用特殊教育,天生就掌握所有語言,包括人類都不會的語言。
此外,這不是GPT的上限,前面提到人類不會的語言GPT也會,一個具體的例子就是“Emoji抽象話生成”。Emoji是互聯網中出現的新符號,根本不算一門語言,更不用說語法了,但是GPT能夠非常流利地使用Emoji和用戶交流,除了Emoji,火星文、抽象文學、字母縮寫也難不住GPT。
4.人格模擬和情感
大部分人其實知道AI實現人格、語氣、情感等擬人化的原理與人類大不相同。但文本是由人創造的,難免帶有創作者的個人烙印,而GPT在吸收了海量的文本后足可自稱“沒有人比我更懂人類”,如果說之前AI模型擬人化只能稱為拙劣的模仿、數字算法的“東施效顰”,那么GPT足夠讓人們感覺它已經達到了真正“扮演”不同人物的水平,如圖1.4所示。
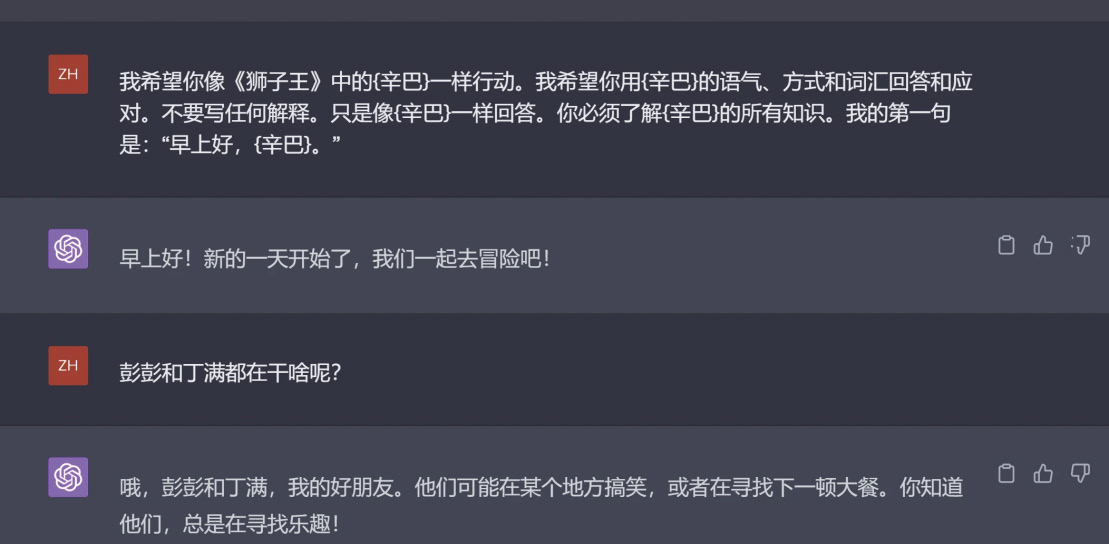
圖1.4 GPT “扮演”不同人物
不僅如此,人們甚至可以通過讓GPT改變不同的人格和身份生成相應內容,這一切會讓人們感覺不到對面是一個AI。