- 計(jì)算機(jī)視覺(jué)的對(duì)象級(jí)場(chǎng)景理解及其應(yīng)用
- 李青
- 12字
- 2023-08-28 20:17:43
1.2 圖像場(chǎng)景理解的發(fā)展歷程
1.2.1 圖像場(chǎng)景語(yǔ)義分割與標(biāo)記
語(yǔ)義是圖像場(chǎng)景理解的重要因素,它從不同角度連接起了圖像場(chǎng)景理解的多個(gè)研究方向,是圖像、語(yǔ)音、文字等多模態(tài)信息應(yīng)用的紐帶。
語(yǔ)義分割,又稱(chēng)為語(yǔ)義標(biāo)記,是計(jì)算機(jī)視覺(jué)、圖像處理、場(chǎng)景理解領(lǐng)域的基礎(chǔ)性問(wèn)題,許多學(xué)者致力于該方向的研究并取得了一定的進(jìn)展。它的目標(biāo)是對(duì)圖像中的每一個(gè)像素賦予唯一的語(yǔ)義類(lèi)別標(biāo)記。圖1-2所示為圖像場(chǎng)景語(yǔ)義分割的目標(biāo),圖1-2a為輸入圖像,圖1-2b為輸入圖像對(duì)應(yīng)的語(yǔ)義分割結(jié)果的可視化,其中不同的顏色代表不同的語(yǔ)義類(lèi)別,如綠色代表草地,藍(lán)色代表羊。

圖1-2 圖像場(chǎng)景語(yǔ)義分割目標(biāo)
早期,學(xué)術(shù)界較多關(guān)注于底層圖像分割,例如,美國(guó)加利福尼亞大學(xué)伯克利分校的計(jì)算機(jī)視覺(jué)研究小組一直關(guān)注于底層圖像分割,并從2000年開(kāi)始,取得了一系列的研究成果[2-6]。底層圖像分割的目標(biāo)是把圖像劃分成不同區(qū)域,雖然每個(gè)區(qū)域不具有對(duì)象和語(yǔ)義的信息,一個(gè)對(duì)象有可能被劃分為多個(gè)區(qū)域,但是至少劃分得到的每個(gè)區(qū)域內(nèi)的像素屬于同一個(gè)對(duì)象。以文獻(xiàn)[3]為例,2003年,該研究小組的成員提出了一種基于分類(lèi)模型的圖像區(qū)域分割方法,該方法適用于二分類(lèi)的問(wèn)題。該研究小組成員認(rèn)為:對(duì)于一張圖像,人手標(biāo)注的分割結(jié)果是這張圖像分割結(jié)果的正樣本,而另一張不相同的甚至差別很大的圖像的人手標(biāo)注分割結(jié)果對(duì)這張圖像分割結(jié)果來(lái)說(shuō)是負(fù)樣本。基于這種假設(shè),該方法根據(jù)信息學(xué)理論,分析輪廓、紋理、亮度等格式塔經(jīng)典特征的作用。最后利用這些特征訓(xùn)練邏輯回歸分類(lèi)器,通過(guò)分類(lèi)器求解圖像的分割結(jié)果,部分結(jié)果如圖1-3所示。可以看到,這種底層分割是區(qū)域的劃分,不具有高層的語(yǔ)義信息和對(duì)象信息。
同時(shí)期,交互式的對(duì)象提取與分割成為一種熱門(mén)的研究方法,有些學(xué)者在這方面進(jìn)行了很多研究工作,得到的成果包括GrabCut[7]、Lazy Snapping[8]、Geodesic Matting[9]等。2004年,英國(guó)微軟劍橋研究院的Rother等提出了GrabCut算法。用戶(hù)只需用方框?qū)⑶熬皩?duì)象框出,在方框以外的像素被默認(rèn)為是背景區(qū)域,前景對(duì)象框即是用戶(hù)給出的先驗(yàn)知識(shí)。該算法通過(guò)構(gòu)建前景對(duì)象和背景區(qū)域的GMM模型,自動(dòng)地將這個(gè)方框中的前景對(duì)象的區(qū)域分割出來(lái),如圖1-4中第一行所示。同年,微軟劍橋研究院的Li等提出Lazy Snapping,即“懶漢摳圖”方法[8]。如圖1-4中第二行所示,在前景和背景上各自標(biāo)記劃線(xiàn),這些劃線(xiàn)離真正的邊界有一定的距離。Lazy Snapping算法取樣劃線(xiàn)上的特征,構(gòu)建前景/背景模型,自動(dòng)求解前景/背景區(qū)域。用戶(hù)還可以在此結(jié)果上增加交互,對(duì)區(qū)域邊界進(jìn)行細(xì)微調(diào)整,完善分割結(jié)果,甚至合成新的場(chǎng)景。類(lèi)似的方法還有2007年美國(guó)明尼蘇達(dá)大學(xué)Bai和Sapiro提出的基于測(cè)地線(xiàn)框架的前景對(duì)象提取方法[9]。另外,還有一些交互式的前/背景分割方法[10-12],也取得了較為快速、魯棒的底層圖像分割結(jié)果。

圖1-3 底層圖像分割結(jié)果[3]

圖1-4 交互式對(duì)象提取與區(qū)域分割[7-9]
雖然底層圖像分割沒(méi)有識(shí)別出每個(gè)區(qū)域的語(yǔ)義信息,只是將具有某種共同屬性的像素劃分為同一個(gè)區(qū)域,但這為圖像語(yǔ)義分割提供了基礎(chǔ)。隨著底層圖像分割和模式識(shí)別技術(shù)的發(fā)展,這兩者的結(jié)合成為一種趨勢(shì)。圖像場(chǎng)景語(yǔ)義分割和標(biāo)記,即同時(shí)得到對(duì)象的語(yǔ)義和區(qū)域輪廓信息,成為計(jì)算機(jī)視覺(jué)熱門(mén)的研究方向,并取得了廣泛的關(guān)注。
2006年,英國(guó)微軟劍橋研究院的Shotton等在ECCV會(huì)議(歐洲計(jì)算機(jī)視覺(jué)會(huì)議)上提出了一種自動(dòng)識(shí)別并分割對(duì)象的方法[13]。該方法作為圖像場(chǎng)景語(yǔ)義分割和標(biāo)記的經(jīng)典代表,為該研究方向的發(fā)展奠定了基礎(chǔ)。該方法繼承了傳統(tǒng)模式識(shí)別的特點(diǎn),開(kāi)創(chuàng)性地提出了一種新穎的特征基元texton,并且提出了一種基于特征基元的濾波器texture-layout。特征基元texton包含了圖像中的紋理特征和形狀特征,濾波器texture-layout則隱性地構(gòu)建了各特征基元texton之間的布局關(guān)系layout。利用模式識(shí)別的學(xué)習(xí)算法,分段學(xué)習(xí)每一部分特征所構(gòu)建的模型,從而快速學(xué)習(xí)出每一種語(yǔ)義類(lèi)別的判別式模型。該方法在訓(xùn)練的過(guò)程中能夠隨機(jī)選擇合適的特征,并且分段學(xué)習(xí)快速得到模型,使得在類(lèi)別繁多的數(shù)據(jù)集中求解場(chǎng)景對(duì)象分割和標(biāo)記成為可能。部分結(jié)果如圖1-5所示,其中第一行和第三行是輸入圖像,第二行和第四行是對(duì)應(yīng)的語(yǔ)義分割和標(biāo)記結(jié)果,不同顏色對(duì)應(yīng)的語(yǔ)義信息顯示在圖中最下方的條形表中。

圖1-5 Textonboost圖像場(chǎng)景語(yǔ)義分割和標(biāo)記[13,14]
隨后有學(xué)者將這種基于模式識(shí)別的思路應(yīng)用于街景圖像的語(yǔ)義分割。2009年,香港科技大學(xué)的Jianxiong Xiao和Long Quan在ICCV會(huì)議(國(guó)際計(jì)算機(jī)視覺(jué)會(huì)議)上提出了一種簡(jiǎn)單有效的多視角下街景圖像的語(yǔ)義分割方法[15]。該方法獲取數(shù)據(jù)的方式是:將數(shù)據(jù)采集設(shè)備固定在汽車(chē)上,在汽車(chē)沿街行駛時(shí)采集街景的2D圖像信息和3D深度信息。為了加速訓(xùn)練過(guò)程和提高識(shí)別的準(zhǔn)確率,該方法自適應(yīng)地為輸入圖像選擇相似的街景圖像序列作為訓(xùn)練數(shù)據(jù)集,這種提高準(zhǔn)確率的訓(xùn)練方式具有一定的啟發(fā)意義(圖1-6)。另外,這種工作框架還能用于實(shí)現(xiàn)大數(shù)量級(jí)3D信息的語(yǔ)義標(biāo)記。

圖1-6 多視角下街景圖像的語(yǔ)義分割[15]
隨著互聯(lián)網(wǎng)技術(shù)的發(fā)展,網(wǎng)絡(luò)逐漸成為一種有效的溝通交流渠道。用戶(hù)通過(guò)互聯(lián)網(wǎng)可以在線(xiàn)共享海量的圖像數(shù)據(jù),例如在線(xiàn)下載LabelMe數(shù)據(jù)集[6]中的圖像。大規(guī)模數(shù)據(jù)的獲得越來(lái)越方便,為數(shù)據(jù)驅(qū)動(dòng)下的非參數(shù)模型方法提供了可能性。這種非參數(shù)模型方法被應(yīng)用到圖像場(chǎng)景語(yǔ)義分割和標(biāo)記中。
2009年,美國(guó)麻省理工學(xué)院的Liu等在CVPR會(huì)議(計(jì)算機(jī)視覺(jué)與圖像識(shí)別會(huì)議)上提出了一種非參數(shù)的場(chǎng)景解析方法(Label Transfer)[17],用于處理場(chǎng)景對(duì)象語(yǔ)義識(shí)別,并第一次將這種非參數(shù)的語(yǔ)義分割方法定義為語(yǔ)義遷移方法。給定一幅輸入圖像,該方法首先利用GIST匹配算法從海量數(shù)據(jù)集里搜索得到輸入圖像的最相似圖像,稱(chēng)之為最近鄰圖像;然后利用一種改進(jìn)的、由粗到細(xì)的SIFT流匹配算法對(duì)這些最近鄰圖像進(jìn)行匹配、評(píng)分,并根據(jù)分值重排序。選擇重排序后的相似圖像作為備選圖像集合。這種SIFT流匹配算法能夠?qū)崿F(xiàn)兩幅圖像的結(jié)構(gòu)對(duì)齊并建立對(duì)應(yīng)關(guān)系。基于這種對(duì)應(yīng)關(guān)系,將備選圖像集合中相似圖像的語(yǔ)義標(biāo)記映射到給定的輸入圖像上并進(jìn)行優(yōu)化,得到圖像場(chǎng)景語(yǔ)義標(biāo)記遷移的最終解,即實(shí)現(xiàn)了輸入圖像的語(yǔ)義分割和標(biāo)記。其過(guò)程如圖1-7所示,圖1-7a為輸入圖像,圖1-7b為通過(guò)SIFT流匹配后的備選圖像集合,圖1-7c為相似圖像的語(yǔ)義標(biāo)記圖,圖1-7d為求解得到的語(yǔ)義標(biāo)記結(jié)果,圖1-7e為語(yǔ)義標(biāo)記的groundtruth。Liu等開(kāi)創(chuàng)性地提出了語(yǔ)義遷移的概念,為后來(lái)學(xué)者開(kāi)辟了一條嶄新的路徑,后續(xù)有很多該領(lǐng)域的研究工作[18-20]。
2010年,美國(guó)麻省理工學(xué)院的Xiao和香港科技大學(xué)的Zhang等在ECCV會(huì)議上提出了一種針對(duì)街景圖像的有監(jiān)督的場(chǎng)景語(yǔ)義遷移方法[19]。該方法認(rèn)為,對(duì)于一張輸入圖像,它不一定與數(shù)據(jù)集中的某一張圖像非常相似,可能只是局部的相似。也就是說(shuō),輸入圖像的某些區(qū)域分別與數(shù)據(jù)集中不同圖像的某些區(qū)域相似。基于這種假設(shè),該方法認(rèn)為應(yīng)該根據(jù)數(shù)據(jù)集中多張不同的圖像來(lái)進(jìn)行語(yǔ)義遷移,而不是僅根據(jù)一張最相似的圖像來(lái)進(jìn)行語(yǔ)義遷移,這是該方法與Label Transfer的區(qū)別所在。如圖1-8所示,給定一幅輸入的街景圖像,該方法首先從已經(jīng)手動(dòng)標(biāo)好語(yǔ)義標(biāo)記的數(shù)據(jù)集中搜索得到多個(gè)小型數(shù)據(jù)集,并且每個(gè)小型數(shù)據(jù)集中都涵蓋了輸入圖像所包含的語(yǔ)義類(lèi)別。利用該方法提出的KNN-MRF匹配機(jī)制,建立輸入圖像和每個(gè)小型數(shù)據(jù)集的對(duì)應(yīng)關(guān)系。利用訓(xùn)練好的分類(lèi)器對(duì)這些對(duì)應(yīng)關(guān)系進(jìn)行分類(lèi),舍棄不正確的對(duì)應(yīng)關(guān)系。在對(duì)應(yīng)關(guān)系分類(lèi)之后,通過(guò)MRF模型優(yōu)化得到輸入圖像的最終語(yǔ)義標(biāo)記結(jié)果。該方法將監(jiān)督學(xué)習(xí)機(jī)制和非參數(shù)的語(yǔ)義遷移方法相結(jié)合,具有一定的借鑒意義。

圖1-7 Label Transfer圖像場(chǎng)景語(yǔ)義遷移結(jié)果[17]
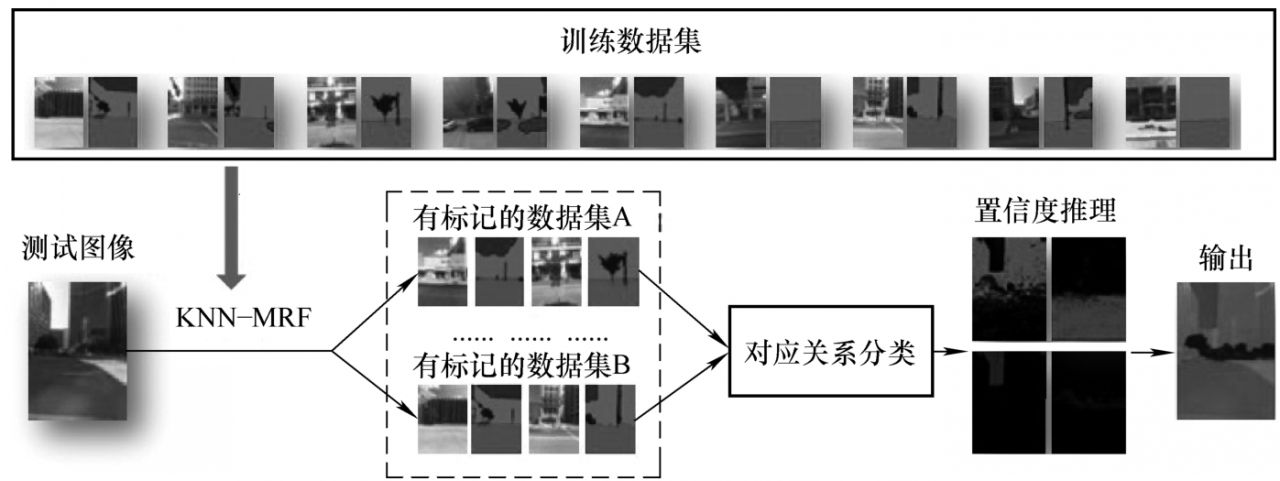
圖1-8 街景圖像的語(yǔ)義遷移結(jié)果[19]
當(dāng)一些圖像場(chǎng)景中存在相似的或相同的對(duì)象時(shí),將多張圖像中的相似對(duì)象同時(shí)分割出來(lái)成為一種需求和趨勢(shì)。微軟劍橋研究院的Rother等提出了對(duì)象共分割的概念[21],認(rèn)為多張圖像相似對(duì)象同時(shí)分割比單獨(dú)一張圖像對(duì)象分割時(shí)能夠提高分割準(zhǔn)確率。此后,許多學(xué)者在對(duì)象共分割的方向上進(jìn)行了探索[22-24]。2012年,卡內(nèi)基梅隆大學(xué)的Kim和Xing在CVPR大會(huì)上,提出一種多張圖像前景對(duì)象共分割方法[25]。該方法針對(duì)的情況是,在一個(gè)圖像集合中有一些重復(fù)多次出現(xiàn)的前景對(duì)象,但每一張圖像中不一定包含所有這些前景對(duì)象,可能只包含一部分,甚至視角也不同。該方法利用圖像集合中多個(gè)前景對(duì)象共存在的先驗(yàn),通過(guò)交互在前景對(duì)象模型和區(qū)域分配模型之間靈活變化,在公共數(shù)據(jù)集上取得了不錯(cuò)的效果,如圖1-9所示。雖然對(duì)象共分割取得了一定的發(fā)展,但是共分割方法還沒(méi)有應(yīng)用于圖像對(duì)象語(yǔ)義分割。

圖1-9 多張圖像前景對(duì)象共分割結(jié)果[25]
2014年,美國(guó)加州大學(xué)默塞德分校的Yang等在CVPR會(huì)議上,提出一種關(guān)注于稀少類(lèi)別的上下文驅(qū)動(dòng)的場(chǎng)景解析方法[26]。場(chǎng)景中的稀少類(lèi)別大多是在場(chǎng)景中所占比例較小或者較少的類(lèi)別,同時(shí)這些稀少類(lèi)別對(duì)場(chǎng)景理解的作用非常重要,而目前大多數(shù)場(chǎng)景解析的方法忽略了這些稀少類(lèi)別的語(yǔ)義標(biāo)記。該方法將語(yǔ)義遷移的方式和增強(qiáng)訓(xùn)練的方式相結(jié)合,如圖1-10所示,根據(jù)檢索得到輸入圖像的相似圖像,并增加相似圖像中稀少類(lèi)別的樣本。在超像素級(jí)別的匹配上,該方法利用上下文信息反饋機(jī)制增加匹配的準(zhǔn)確度,構(gòu)建MRF模型并求解最終語(yǔ)義標(biāo)記結(jié)果。
卷積神經(jīng)網(wǎng)絡(luò)(Convolutional Neural Networks, CNN)是深度學(xué)習(xí)的代表算法,近年來(lái)廣泛應(yīng)用于目標(biāo)檢測(cè)、識(shí)別、圖像分類(lèi)方面,取得了突破性的進(jìn)展,效果顯著提升。卷積神經(jīng)網(wǎng)絡(luò)除了輸入輸出外通常包含卷積層(Convolutional layer)、線(xiàn)性整流層(ReLU layer)、池化層(Pooling layer)和全連接層(Fully-Connected layer)。卷積層的功能是對(duì)輸入數(shù)據(jù)進(jìn)行特征提取,在感受野區(qū)域利用卷積核操作提取局部特征。池化層通過(guò)降采樣(downsamples)對(duì)卷積層的輸出特征進(jìn)行選擇,減少模型參數(shù)訓(xùn)練的復(fù)雜度,提高所提取特征的魯棒性。全連接層對(duì)提取的特征進(jìn)行非線(xiàn)性組合,以得到回歸分類(lèi)輸出。
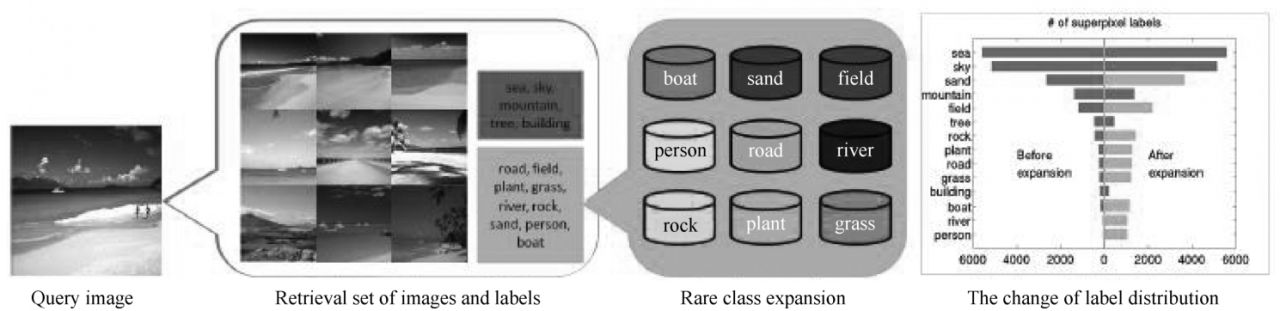
圖1-10 關(guān)注于稀少類(lèi)別的上下文驅(qū)動(dòng)的場(chǎng)景解析方法[26],藍(lán)色矩形中為普通類(lèi)別,黃色矩形中為稀少類(lèi)別,在右邊的條形類(lèi)別分布圖中可看到,增強(qiáng)后的稀少類(lèi)別樣本(黃色)比增強(qiáng)前(藍(lán)色)分布更均衡
卷積神經(jīng)網(wǎng)絡(luò)的第一個(gè)成功應(yīng)用是由Yann LeCun提出的LeNet結(jié)構(gòu)[27],應(yīng)用在手寫(xiě)字體識(shí)別上。此后,卷積神經(jīng)網(wǎng)絡(luò)的特征學(xué)習(xí)能力得到了關(guān)注,并伴隨著龐大的標(biāo)注數(shù)據(jù)集的出現(xiàn)以及計(jì)算機(jī)硬件性能的提高(如GPU),推動(dòng)了深度學(xué)習(xí)的發(fā)展。ILSVRC(ImageNet Large Scale Visual Recognition Challenge)是近年來(lái)視覺(jué)領(lǐng)域權(quán)威學(xué)術(shù)競(jìng)賽之一,競(jìng)賽使用的數(shù)據(jù)集ImageNet是由斯坦福大學(xué)李飛飛教授等人于2009年提出的,隨后從2010年開(kāi)始每年舉辦一屆比賽,直到2017年。歷年來(lái)的ILSVRC挑戰(zhàn)賽上,不斷涌現(xiàn)出優(yōu)秀的算法和模型,例如2012年的AlexNet[28]、2013年的ZF Net[29]、2014年的GoogLeNet[30]和VGGNet[31]、2015年的ResNet[32](殘差神經(jīng)網(wǎng)絡(luò))。
首次在計(jì)算機(jī)視覺(jué)中普及深層卷積網(wǎng)絡(luò)的是AlexNet,該網(wǎng)絡(luò)的基本架構(gòu)與LeNet類(lèi)似,但其網(wǎng)絡(luò)結(jié)構(gòu)更深、更大,并成功應(yīng)用了ReLU、Dropout,取得了遠(yuǎn)超第二名的結(jié)果。ZF Net是對(duì)AlexNet的改進(jìn),它調(diào)整了結(jié)構(gòu)的參數(shù),通過(guò)可視化技術(shù)揭示了各層的作用,從而能夠幫助選擇好的網(wǎng)絡(luò)結(jié)構(gòu),并遷移到其他數(shù)據(jù)集。GoogLeNet是2014年ILSVRC的冠軍,它的主要貢獻(xiàn)是提出了Inception架構(gòu),使用已有的稠密組件來(lái)近似卷積網(wǎng)絡(luò)中的最優(yōu)局部稀疏結(jié)構(gòu),大大減少了網(wǎng)絡(luò)中的參數(shù)數(shù)量,更高效地利用計(jì)算資源。此外,架構(gòu)在頂部使用平均池(average pooling)來(lái)代替全連接層,消除了大量似乎無(wú)關(guān)緊要的參數(shù)。VGGNet是2014年ILSVRC的亞軍,它證明了通過(guò)增加網(wǎng)絡(luò)的深度可實(shí)現(xiàn)對(duì)現(xiàn)有技術(shù)性能的顯著改進(jìn)。該網(wǎng)絡(luò)包含16~19層,并且整個(gè)網(wǎng)絡(luò)都使用了同樣大小的3×3卷積核和2×2池化核。VGGNet遷移到其他數(shù)據(jù)上的泛化性也比較好,是當(dāng)前提取圖像特征常用的網(wǎng)絡(luò)模型,并且在Caffe中可以下載使用預(yù)訓(xùn)練模型。它的缺點(diǎn)是參數(shù)量較多,需要較大的存儲(chǔ)空間(140M)。由微軟研究院Kaiming He等人開(kāi)發(fā)的殘差網(wǎng)絡(luò)ResNet是ILSVRC 2015的獲勝者,它的提出是為了簡(jiǎn)化深度模型的訓(xùn)練。它在架構(gòu)上使用殘差學(xué)習(xí),使得網(wǎng)絡(luò)深度增加時(shí)沒(méi)有出現(xiàn)退化問(wèn)題,讓深度發(fā)揮出作用。
卷積神經(jīng)網(wǎng)絡(luò)在目標(biāo)檢測(cè)、識(shí)別、分類(lèi)方面取得了突破性的進(jìn)展,而語(yǔ)義分割可以認(rèn)為是一種稠密的分類(lèi),即實(shí)現(xiàn)每一個(gè)像素所屬類(lèi)別的分類(lèi),因此基于卷積神經(jīng)網(wǎng)絡(luò)的語(yǔ)義分割成為自然而然的趨勢(shì)。2015年,加州大學(xué)伯克利分校的研究人員將卷積神經(jīng)網(wǎng)絡(luò)引入語(yǔ)義分割的領(lǐng)域內(nèi),首次提出全卷積網(wǎng)絡(luò)(FCN)[33],是語(yǔ)義分割進(jìn)入深度學(xué)習(xí)時(shí)代的里程碑。FCN網(wǎng)絡(luò)結(jié)構(gòu)是不含全連接層的全卷積網(wǎng)絡(luò),把CNN網(wǎng)絡(luò)中的全連接層都換成卷積層,這樣就可以獲得二維的特征圖,再利用反卷積層對(duì)特征圖進(jìn)行上采樣,使它恢復(fù)到與原圖相同的尺寸進(jìn)行分類(lèi),輸出與原圖大小相同的像素級(jí)分類(lèi)結(jié)果,即dense prediction,如圖1-11所示。FCN可以接受輸入任意大小的圖片,不再受限于CNN的區(qū)域輸入。

圖1-11 場(chǎng)景語(yǔ)義分割的全卷積網(wǎng)絡(luò)FCN[33],將全連接層轉(zhuǎn)換為卷積層使得分類(lèi)網(wǎng)絡(luò)能夠輸出與圖像相同尺寸的熱圖
雖然FCN實(shí)現(xiàn)了基于卷積網(wǎng)絡(luò)像素級(jí)語(yǔ)義分割的稠密預(yù)測(cè),但得到的結(jié)果還不夠精細(xì),圖像中的邊緣細(xì)節(jié)部分比較模糊和平滑,缺少了空間關(guān)系的考慮。許多研究人員在CNN和FCN網(wǎng)絡(luò)模型的基礎(chǔ)上進(jìn)行改進(jìn),陸續(xù)提出了一系列的基于卷積網(wǎng)絡(luò)的語(yǔ)義分割算法。
例如,劍橋大學(xué)的SegNet網(wǎng)絡(luò)[34],由編碼器網(wǎng)絡(luò)、相應(yīng)的解碼器網(wǎng)絡(luò)以及像素級(jí)分類(lèi)層組成。其編碼器網(wǎng)絡(luò)的結(jié)構(gòu)與VGG16網(wǎng)絡(luò)的13個(gè)卷積層相同,解碼器網(wǎng)絡(luò)的作用是將低分辨率的編碼器特征映射到與輸入相同分辨率的特征圖,以便進(jìn)行像素級(jí)分類(lèi),這種映射需要有助于精確邊界定位的特征。SegNet的新穎之處在于,在編碼時(shí)為最大池化計(jì)算池索引(pooling indices),在對(duì)應(yīng)的解碼時(shí)使用池索引來(lái)執(zhí)行非線(xiàn)性上采樣,這樣就不需要訓(xùn)練學(xué)習(xí)上采樣,同時(shí)改進(jìn)了邊界劃分。韓國(guó)科研人員認(rèn)為FCN網(wǎng)絡(luò)中固定大小的感受野可能引起錯(cuò)誤的標(biāo)記,過(guò)大的對(duì)象可能會(huì)標(biāo)記為不同類(lèi)別,或者過(guò)小的對(duì)象被忽略或記為背景。再者,由于輸入到反卷積層的標(biāo)簽圖過(guò)于粗糙、反卷積過(guò)程過(guò)于簡(jiǎn)單,常常會(huì)丟失或平滑掉對(duì)象的結(jié)構(gòu)細(xì)節(jié)。因此,他們提出一種多層的反卷積網(wǎng)絡(luò)DeconvNet[35]。DeconvNet網(wǎng)絡(luò)由卷積網(wǎng)絡(luò)部分和反卷積網(wǎng)絡(luò)部分組成,卷積網(wǎng)絡(luò)部分使用了VGG16,反卷積網(wǎng)絡(luò)部分由反卷積(deconvolution)層、上池化(unpooling)層和激活函數(shù)(rectifiedlinear unit, ReLU)層組成。訓(xùn)練好的網(wǎng)絡(luò)可以得到實(shí)例級(jí)的分割結(jié)果,然后將這些分割結(jié)果進(jìn)行合并,得到最終的語(yǔ)義分割結(jié)果。
DilatedNet[36]是在不丟失分辨率的情況下聚合多尺度上下文信息的卷積網(wǎng)絡(luò)模塊,由普林斯頓大學(xué)和英特爾實(shí)驗(yàn)室專(zhuān)門(mén)為稠密預(yù)測(cè)而設(shè)計(jì)。它是一個(gè)卷積層的矩形棱鏡,沒(méi)有池化或子采樣。該模塊基于擴(kuò)展卷積,支持感受野的指數(shù)擴(kuò)展,而不損失分辨率或覆蓋范圍,可以以任何分辨率插入現(xiàn)有網(wǎng)絡(luò)體系結(jié)構(gòu)。Deeplab[37]是谷歌團(tuán)隊(duì)結(jié)合了深度卷積神經(jīng)網(wǎng)絡(luò)(DCNNs)和概率圖模型(DenseCRFs)兩類(lèi)方法而得到的系列網(wǎng)絡(luò)模型,目前已更新4個(gè)版本。其主要?jiǎng)?chuàng)新之處在于:①對(duì)不同尺度大小的對(duì)象,提出多孔空間金字塔池化(ASPP)模塊,在卷積之前以多種采樣率在給定的特征層上進(jìn)行重采樣;②使用全連接條件隨機(jī)場(chǎng)(CRF)來(lái)恢復(fù)局部結(jié)構(gòu)的細(xì)節(jié),將每個(gè)像素視為CRF節(jié)點(diǎn),使用CRF推理優(yōu)化,得到邊緣輪廓更清晰的分割結(jié)果。
RefineNet[38]是由澳大利亞阿德萊德大學(xué)研究人員提出的一種基于FCN的多路徑優(yōu)化網(wǎng)絡(luò),他們認(rèn)為各層的特征都有助于語(yǔ)義分析分割,高層的語(yǔ)義特征有助于圖像區(qū)域的類(lèi)別識(shí)別,而低層的視覺(jué)特征有助于生成清晰、細(xì)致的邊界。因此,RefineNet利用了下采樣過(guò)程中的所有可用信息,使用遠(yuǎn)程殘差連接實(shí)現(xiàn)高分辨率預(yù)測(cè),淺層卷積層獲得的細(xì)顆粒度特征可以直接以遞歸的方式優(yōu)化深層獲得的高層語(yǔ)義特征。RefineNet中的所有組件都使用恒等映射的殘差連接,這樣梯度能夠通過(guò)短距離和長(zhǎng)距離的殘差連接傳播,從而實(shí)現(xiàn)高效的端到端訓(xùn)練。同時(shí)還提出了鏈?zhǔn)綒埐畛鼗K,使用多個(gè)窗口尺寸獲得有效的池化特征,并使用殘差連接和學(xué)習(xí)到的權(quán)重融合到一起,從而在較大的圖像區(qū)域獲得背景上下文。
通過(guò)分析國(guó)內(nèi)外研究現(xiàn)狀發(fā)現(xiàn),在深度學(xué)習(xí)時(shí)代之前,圖像場(chǎng)景語(yǔ)義分割的方法主要分為有參數(shù)解析方法和非參數(shù)解析方法,這兩類(lèi)方法基本上都是手工設(shè)定所需特征并進(jìn)行處理,通過(guò)構(gòu)建CRF或者M(jìn)RF模型來(lái)進(jìn)行優(yōu)化求解。而前/背景分割方法一般不需要構(gòu)建CRF或者M(jìn)RF模型,因此能夠快速得到分割結(jié)果,但是這類(lèi)方法只能處理二類(lèi)對(duì)象的分割問(wèn)題。因此如何將前兩類(lèi)方法與后一類(lèi)方法的優(yōu)勢(shì)相結(jié)合,應(yīng)用到圖像場(chǎng)景語(yǔ)義分割上,成為一個(gè)值得考慮的問(wèn)題。在深度學(xué)習(xí)時(shí)代,卷積神經(jīng)網(wǎng)絡(luò)在特征提取和計(jì)算能力上具有顯著的優(yōu)勢(shì),包括上述典型網(wǎng)絡(luò)模型在內(nèi)的許多基于卷積神經(jīng)網(wǎng)絡(luò)的方法,基本處理方式都是前端使用CNN/FCN進(jìn)行特征粗提取,后端使用CRF/MRF場(chǎng)結(jié)構(gòu)模型優(yōu)化前端的輸出,改善前端邊緣細(xì)節(jié)的劃分,最后得到分割圖。
- 人工智能開(kāi)發(fā)語(yǔ)言:Python
- 深度探索:解碼DeepSeek及人工智能的未來(lái)
- 解構(gòu)ChatGPT
- 人工智能3.0:大智若愚
- AI落地:讓人工智能為你所用
- 機(jī)器學(xué)習(xí)公式詳解(第2版)
- Arduino開(kāi)發(fā)實(shí)戰(zhàn)指南:機(jī)器人卷
- 2019年華北五省(市、自治區(qū))大學(xué)生機(jī)器人大賽:人工智能與機(jī)器人創(chuàng)意設(shè)計(jì)賽論文集
- 智能浪潮:增強(qiáng)時(shí)代來(lái)臨
- 生成式AI實(shí)戰(zhàn)
- 人工智能及其應(yīng)用
- AI:人工智能的本質(zhì)與未來(lái)
- 被人工智能操控的金融業(yè)
- 聊天機(jī)器人:對(duì)話(huà)式體驗(yàn)產(chǎn)品設(shè)計(jì)
- 如何創(chuàng)造思維:人類(lèi)思想所揭示出的奧秘