- 深度學習原理與應用
- 周中元 黃穎 張誠 周新
- 918字
- 2021-04-30 22:05:40
3.7 隨機梯度下降法
誤差反向傳播算法先對損失函數計算梯度,然后計算連接權重調整值,通過反復迭代訓練,最終獲得符合預期要求的解。
現在可以很容易地獲得大量數據用于訓練,將所有數據都用于神經網絡的訓練當然得到的效果會更好,但付出的代價也很大,需要大量的計算力和計算時間。在工程實踐中,經常需要回答的問題是,如何不失一般性地在為數眾多的訓練數據中選取適當的訓練樣本?所謂不失一般性,就是要使訓練樣本數據的數字特征盡可能地與總體數據的數字特征一致,從而使樣本數據得到的最優解就是全體數據的最優解。隨機梯度下降收斂圖如圖3-33所示。
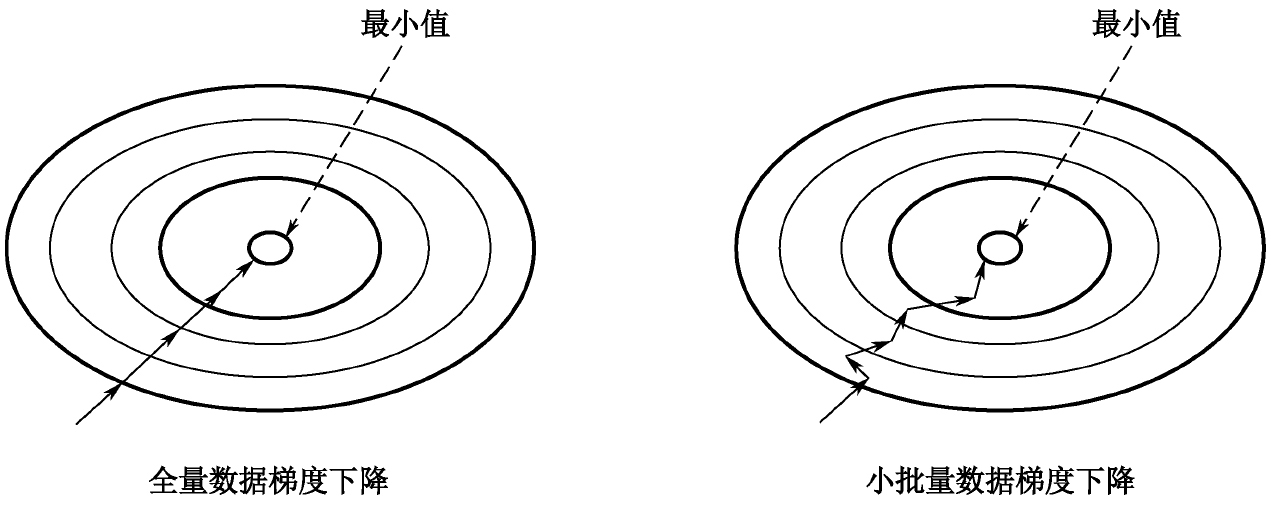
圖3-33 隨機梯度下降收斂圖示
從圖3-33中可以看出,由于每次的訓練數據集不相同,相應的梯度值也不同,所以向最小值收斂的路徑是隨機曲折向前的。
誤差反向傳播算法有三種樣本選取方式:
(1)批量學習(batch learning)算法:在每次進行迭代計算時,需要遍歷全部訓練樣本。假定第t次迭代時各訓練樣本的誤差為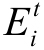 ,全部訓練樣本的誤差Et為:
,全部訓練樣本的誤差Et為:
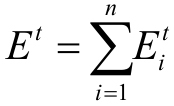
批量學習由于每次迭代都計算全部訓練樣本,所以能夠有效抑制噪聲樣本所導致的輸入模式劇烈變動,但訓練時間較長。
(2)在線學習(sequential learning或online learning)算法:這種算法每輸入一個訓練樣本,就進行一次迭代,然后使用調整后的連接權重測試下一個訓練樣本。
由于每次只計算一個訓練樣本,所以訓練樣本的差異可能導致迭代結果出現大幅變動,這樣會導致訓練無法收斂。
為此,可以采取逐步降低學習率η,但這不能保證徹底解決此問題。
(3)小批量(mini-batch)梯度下降學習算法:這種算法介于在線學習和批量學習之間,它將訓練集分成幾個子集,每次使用其中一個子集。
由于每次迭代只使用少量樣本,與批量學習相比,能夠縮短單次訓練時間。由于每次迭代使用了多個訓練樣本,與在線學習相比,能夠減少結果變動。
小批量和在線學習使用部分訓練樣本進行迭代計算,部分的選取是隨機的,所以稱隨機梯度下降法(Stochastic Gradient Descent,SGD)。
SGD法每次抽取部分訓練樣本,所以減少了迭代結果陷入局部最優的情況,是目前深度學習的主流算法。當然,SGD法不可避免地會出現在搜索最優路徑中的“徘徊”情況,因為不可能每次選取的樣本所算出的梯度方向就是目標函數值下降最大的方向。于是有學者提出了取代SDG的AdaGrad、Momentum、Adam等方法,在3.5.6節中也提到了這些方法。